A Beginner’s Guide to Credit Card Fraud Detection using Machine Learning

Introduction
Machine Learning (ML) is an increasingly popular field focusing on building algorithms that “learn” and improve from data. ML is often confused with AI — the main difference lies in the fact that AI programs are often more complex and meant to simulate some facet of human behaviour.
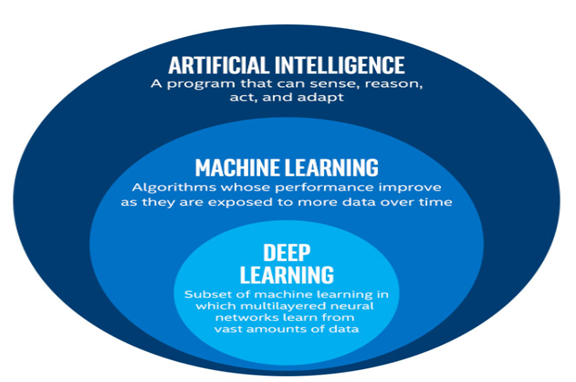
Often, the focus in an ML task is to just find an optimal algorithm which is able to map some independent variable(s) to the dependent variable in a set of data so any future test cases can be evaluated successfully.
Glossary of Common Terms
Dataset — a collection of any form of data (photos, audio files, etc.)
Model — an algorithm which has been trained to recognize patterns in a specific dataset
Training and testing (set)— A model is first given a training set of data so the algorithm is able to “learn” and adjust any weights/biases so input is evaluated correctly. The model is then given the test set of data to evaluate its performance and the effectiveness.
Classification — A type of ML problem where the desired output is some class label. For example, given an image, a classification model would evaluate if it is a dog or cat.
Regression — A type of ML problem where the desired output is some continuous quantity. For example, given the number of bedrooms and washroom, square footage, and location, a regression model could evaluate a likely price for the house.
Problem Statement
Imagine you are employed by a credit card company to detect any possible fraudulent transactions so customers can be assured they will only be charged for items they purchased. To complete this task, you are given a dataset from which you should develop a predictive model that can classify any credit card transactions as non fraudulent or fraudulent.
The dataset used can be found here: https://www.kaggle.com/mlg-ulb/creditcardfraud

Problem Solving Process
Machine Learning problems are complex and multi-step. Here is the general procedure we will follow to develop a solution to this problem.
1. Setup Python environment
2. Complete an exploratory data analysis
3. Preprocess the data
4. Build a variety of classification models to analyze which works best with the dataset (since each transaction is either fraudulent or not, this is a classification problem)
5. Evaluate each of the models with a common set of evaluation metrics
Setup Python environment
Starting virtual environment and installing necessary packages
Create a directory to house your project files. Then, open the command line and navigate to this directory. Create and activate a virtual environment by typing the following commands.
virtualenv env
source env/bin/activateAny packages installed while the virtual environment is active will only be installed for this project directory. This helps to better organize the packages necessary for each project and ensures that there are no incompatibility issues.
Next, type the following command to install the necessary packages.
pip3 install pandas matplotlib sklearn numpy seabornImporting the necessary packages and dataset into Python
Add the downloaded dataset to the project folder. Next, create a new file called main.py and save it in the same folder. Open main.py and add the following lines to import the packages we will be working with.
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler, RobustScaler
import seaborn as sns
import warnings
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import precision_score, accuracy_score, classification_report, confusion_matrix
from sklearn.model_selection import cross_val_scoreFinally, import the dataset into Python and print a few sample rows to get a glimpse into how it looks.
df = pd.read_csv('./creditcard.csv')
print (df.head())Output:

The “Time” column specifies the time, in seconds, that a transaction was recorded over a period of 2 days.
Columns “V1” to “V28” are each different numerical features pertaining to the transaction. Extra details regarding the nature of each feature are not given to prevent confidentiality issues. Additionally, the numbers given in each of these columns have also been PCA transformed (modified using an algorithm to further ensure security).
Finally, the column “Amount” specifies how much money was involved in each transaction and “Class” denotes whether it was fraudulent or non-fraudulent (0 for non-fraudulent and 1 for fraudulent).
Complete an Exploratory Data Analysis
A crucial step before devising a solution for a ML problem is to first better understand the data. This is because datasets often have flaws, such as being imbalanced, containing invalid data, and having missing fields. Therefore, these issues must be addressed in the preprocessing stage before any models are built.
Dataset Composition
First, lets get an idea of how many fraudulent and non-fraudulent transactions are in the dataset.
print('Non Fraudulent transactions:', len(df[df.Class == 0]))
print('Fraudulent transactions:', len(df[df.Class == 1]))
print("Percentage of fraudulent transactions", len(df[df.Class == 1])/len(df))Output:

Obviously, this is an incredibly unbalanced dataset as only a minute fraction of all entries are fraudulent transactions. If a model is trained on this, it can exhibit unpredictable behaviour because it simply does not have enough fraudulent transaction examples to learn from. Therefore, this is an area to address during preprocessing.

Null/Empty Values
If a dataset has any empty values, these must addressed before model training. Often, any such null values are filled with the average of the other values in the same column.
We can check for null values by running the following line:
print (df.isnull().sum().max())Output:

We have no null values, which is great — a headache dodged.
Scaling Check
One possible area of concern I noticed when printing the top of the dataset was the wide gap between values in the “Amount” column. To check if this is a trend across the dataset, we can utilize the describe function in the Pandas library.
print('Non-Fraudulent transactions "Amount" column statistics:')
print (df[df.Class==0]['Amount'].describe())
print('Fraudulent transactions "Amount" column statistics:')
print (df[df.Class==1]['Amount'].describe())
The high standard deviation and large difference between 25th, 50th, and 75th percentiles mean that this column has a wide range in values and should be scaled in the preprocessing stage.
Redundant Features
Finally, the “Time” column is redundant because it offers no insight into the data — it's just an arbitrary data point. For this reason, the column can be removed before building any models.
Preprocess the data
In this stage, we take the information gleaned in the EDA and apply it to modify the dataset.
Lets do the easy stuff first. As we noticed, the “Time” column serves no use so it can be dropped.
df.drop("Time", axis=1, inplace=True)Next, lets scale the “Amount” column. We can use the StandardScaler class from sklearn.
s = StandardScaler()
df['Amount'] = s.fit_transform(df['Amount'].values.reshape(-1, 1))Finally, we have to deal with the inherent imbalance in our dataset. This is a great time to introduce a crucial concept applicable in a wide variety of ML problems — overfitting vs underfitting. The next portion will focus on explaining this concept in detail, so feel free to skip it to see how it is applied in this situation.
The easiest way to introduce this concept is through a real world example. In all my classes, I’ve always encountered 3 types of students — lets call them Jane, Liam, and Josh:
Jane — Couldn’t care less about what is being taught
Liam — Memorize the textbook and spend the entire class copying down the lecture word for word
Josh — Seek to learn the fundamental concepts being taught
Now, let us assume that the classwork is assigned daily is filled with questions that reflect what was taught that specific day. Also, a quiz is given at the end of each week that contains questions the students have not seen before. Here is how each student would fare:
Jane — Poor grade on both the classwork and quiz as she doesn't study at all
Liam — High mark on classwork and a poor mark on the quiz as he simply memorizes answers to the questions he has seen
Josh — Above-average mark on both classwork and the quiz because he understands, on a conceptual level, how to solve the problems
Now, tying this back to machine learning, we can equate “classwork” to the training dataset of a model and the “quiz” to the testing dataset. An underfitting model behaves similar to Jane and scores poorly on both datasets. An overfitting model behaves similar to Liam and conforms too closely to the training set — including its possible noise and outliers — which leads to poor test set performance. Josh represents the ideal balance between underfitting and overfitting where the model exhibits strong performance on both training sets.
In our dataset, the vast majority of non-fraudulent cases could cause overfitting, where a model will follow the trend of the dataset and assume that fraudulent cases are close to non-existent in the real world — which is wrong.
One way to approach this issue is by taking a sub-sample of the dataset where the number of fraudulent and non-fraudulent entries are equal. This can be done through a technique called Random Under-Sampling.
df = df.sample(frac=1)
num_fraud = len(df[df.Class == 1])
fraud_entries = df[df.Class == 1]
non_fraud_entries = df[df['Class'] == 0][:num_fraud]
random_undersampled_df = pd.concat([fraud_entries, non_fraud_entries])
random_undersampled_df = random_undersampled_df.sample(frac=1, random_state=42)Essentially, we first shuffle the dataset, find the number of fraudulent entries, separate the original dataset by class — taking only the desired number of fraudulent entries — and then put the seperated entries together into a new dataset. Keep in mind this is not a technique that can used all the time and will likely not eliminate the problem completely. More effective techniques, such as SMOTE, can be used instead, but we will stick to Random Under-Sampling for now because of its simplicity.
Finally, lets do a quick check to see that our sub-sample has an equal number of fraudulent and non fraudulent entries.
print(new_df['Class'].value_counts()/len(new_df))
sns.countplot('Class', data=new_df, palette=["#0488d0", "#539100"])
plt.title('Class Distribution after Random Under-Sampling', fontsize=14)
plt.show()Output:

Looks equal to me. Lets move on.
Building Classification Models
We will build a variety of classification models in this section and then test them out individually to see which are the best suited for this task.
Types of models
A brief description of the models we will build is provided below:
1. Decision Tree: This algorithm works similar to a tree data structure. Any data given to model starts at the top, or root node, and moves down the tree while being sorted at each node is passes through until it reaches some terminal node (output class).
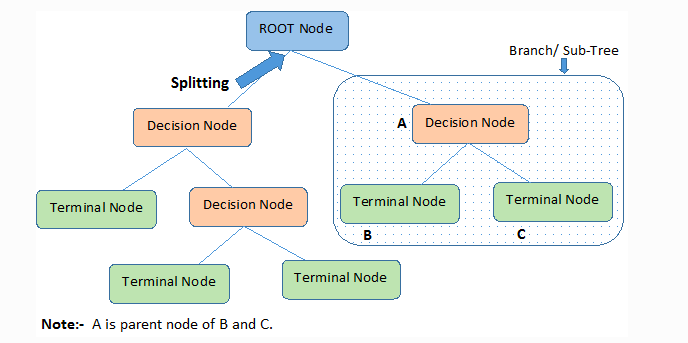
Lets take a real world example to see how this would work when trying to recognize desserts while blindfolded. Does it have a solid consistency? If so, does it taste spongy? If so, is there icing? This process would continue until you run out of binary questions, leaving you with an answer.
2. Random Forest Tree Classifier: An extension of the previous model, this algorithm just consists of several different decision trees working as an ensemble — each of them evaluates the input and reaches some output. All outputs are then consolidated and the class with the most votes is chosen as the model’s prediction. The idea behind this is simple — 2 (or more) brains should be better than 1 (sometimes).
3. K-Nearest Neighbours (KNN): This algorithm makes the key assumption that similar things stick together. After providing some number k and a piece of data, a KNN model will find the k closest data points it knows to the data provided and take the average to find the output. This is depicted graphically in the following diagram, where the green dot is the data provided and k=3.

One important factor to consider with KNN is that the value for k must be determined experimentally based on the dataset and task — too low a value could result in fluke errors while too high could result in inaccuracy as the algorithm picks up excessive noise and outliers in the dataset.
4. Logistic Regression: This is a very intuitive algorithm and is often implemented for simple categorical problems, such as this one. Given a dataset, a linear function is constructed. Any test cases are given to the function as input — the output of which is a measure of confidence that the testcase is positive.

In the graph above, the linear function, or regression line, represents the numerical confidence that a given height is from a male. This confidence is then given to a sigmoid function which outputs a 0 or 1, corresponding to female or male respectively.
Programming
Now, lets get down to coding. First, we will use train_test_split to split our sub-sample dataset into a training and test set.
x = random_undersampled_df.drop("Class", axis=1)
y = random_undersampled_df["Class"]
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=42)Next, we will initialize and train each of our models on the training set.
#Decision Tree
tree_model = DecisionTreeClassifier(max_depth = 4, criterion = 'entropy')
tree_model.fit(x_train, y_train)#Random Forest Tree
rf = RandomForestClassifier(max_depth = 4)
rf.fit(x_train, y_train)#K-Nearest Neighbors
k = 5
knn = KNeighborsClassifier(n_neighbors = k)
knn.fit(x_train, y_train)#Logistic Regression
lr = LogisticRegression()
lr.fit(x_train, y_train)
Finally, lets check out the training score of our model. We will do this through a technique called cross validation. In this technique, the training dataset is split into k subsets of equal size and the model is trained on all but one of the subsets. The remaining subset acts as a test set and is given to the model to evaluate accuracy. This process is repeated until all of the subsets have been given as a test set once and the average of all the accuracies is returned.
print('Training score of the Decision Tree model is {}'.format(cross_val_score(tree_model, x_train, y_train, cv=5).mean()))
print('Training score of the KNN model is {}'.format(cross_val_score(knn, x_train, y_train, cv=5).mean()))
print('Training score of the Logistic Regression model is {}'.format(cross_val_score(lr, x_train, y_train, cv=5).mean()))
print('Training score of the Random Forest Tree model is {}'.format(cross_val_score(rf, x_train, y_train, cv=5).mean()))Output:

Remember that these are all scores out of 1 — for example, the percentage score of the Decision Tree model is actually 91.8% (0.918 * 100).
Looks like the Logistic Regression model performed best during training.
Evaluating the Models Using Common Metrics
Our models will be evaluated using the accuracy score and confusion matrix.
Description of each metric
Accuracy Score: By far the most intuitive way to measure the effectiveness of a model. Simply divide the number of correct predictions by the total predictions made by the model.
Accuracy = # correct predictions / # total predictions
Confusion Matrix: A confusion matrix helps provide a number of insights into the model’s effectiveness in a visual form.

In the above diagram, “a” represents True Positives, “b” represents True Negatives, “c” represents False Positives, and “d” represents False Negatives. Using these values, Positive/Negative Predictive Value, Sensitivity, Specificity, and Accuracy can all be calculated.
Programming
We will evaluate our model on two test sets — one from our sub-sampled dataset and one from the original dataset. This is to get a better idea of the model’s performance when the data is imbalanced.
We can generate a test set for our original dataset by using train_test_split.
ox = df.drop("Class", axis=1)
oy = df["Class"]
ox_train, ox_test, oy_train, oy_test = train_test_split(ox, oy, test_size=0.2, random_state=42)Accuracy:
We will use the accuracy_score function from sklearn.
print('Accuracy score of the Decision Tree model on the sub-sampled test set is {}'.format(accuracy_score(y_test, tree_model.predict(x_test))))
print('Accuracy score of the KNN model on the sub-sampled test set is {}'.format(accuracy_score(y_test, knn.predict(x_test))))
print('Accuracy score of the Logistic Regression model on the sub-sampled test set is {}'.format(accuracy_score(y_test, lr.predict(x_test))))
print('Accuracy score of the Random Forest Tree model on the sub-sampled test set is {}'.format(accuracy_score(y_test, rf.predict(x_test))))print ('---------------------------------------------')print('Accuracy score of the Decision Tree model on the original test set is {}'.format(accuracy_score(oy_test, tree_model.predict(ox_test))))
print('Accuracy score of the KNN model on the sub-sampled original test set is {}'.format(accuracy_score(oy_test, knn.predict(ox_test))))
print('Accuracy score of the Logistic Regression model on the original test set is {}'.format(accuracy_score(oy_test, lr.predict(ox_test))))
print('Accuracy score of the Random Forest Tree model on the original test set is {}'.format(accuracy_score(oy_test, rf.predict(ox_test))))
Output:

As we can see, the Logistic Regression model scored highest on the sub-sampled dataset (~96%) and the Random Forest Tree model scored highest on the original test set (~99%).
Confusion Matrix
We will use the confusion_matrix function from sklearn and create a heatmap using seaborn. To avoid taking up too much space, I will show how to create a confusion matrix for just the Logistic Regression model on the sub-sampled test set — you may just swap the model and test set if you wish.
#change the model and test set here if you wish
m = confusion_matrix(y_test, lr.predict(x_test))ax = sns.heatmap(m, annot=True, cmap='Blues')
ax.set_title('Seaborn Confusion Matrix with labels\n\n');
ax.set_xlabel('\nPredicted Values')
ax.set_ylabel('Actual Values ');
ax.xaxis.set_ticklabels(['False','True'])
ax.yaxis.set_ticklabels(['False','True'])
plt.show()
Output:

We can quickly analyze the false positives and negatives that our model outputted using the confusion matrix. Taking the top row, it looks like we had 82 + 5 = 87 total non fraudulent test cases in the test set. Of these, the model correctly predicted 82. Therefore, it has an accuracy of ~94% for non-fraudulent test cases in this set. On the second row, we had 10 + 100 = 110 fraudulent test cases in the test set. Of these, the model correctly predicted 100. In this way, it has an accuracy of ~91% for fraudulent test cases in this set.
Final Thoughts
Hopefully this article presented an easy-to-follow guide on how to implement credit card fraud detection using ML and how to approach such problems in general. There are many more models and techniques (ex. SMOTE) that could have been tested as well to possibly improve the effectiveness of our solution, but the main focus of this guide was to develop a basic working prototype and clearly articulate the process.
Thank you for reading this article! If it helped, please consider connecting on LinkedIn — I’d love to hear your thoughts.
Here is the full code:
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler, RobustScaler
import seaborn as sns
import warnings
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import precision_score, recall_score, f1_score, roc_auc_score, accuracy_score, classification_report
from sklearn.model_selection import cross_val_scorewarnings.filterwarnings("ignore")df = pd.read_csv('./creditcard.csv')print('Non-Fraudulent transactions "Amount" column statistics:')
print (df[df.Class==0]['Amount'].describe())
print('Fraudulent transactions "Amount" column statistics:')
print (df[df.Class==1]['Amount'].describe())# dropping redundant column and scaling "Amount" feature
df.drop("Time", axis=1, inplace=True)
s = StandardScaler()
df['Amount'] = s.fit_transform(df['Amount'].values.reshape(-1, 1))#performing Random Under-Sampling
df = df.sample(frac=1)
num_fraud = len(df[df.Class == 1])
fraud_entries = df[df.Class == 1]
non_fraud_entries = df[df['Class'] == 0][:num_fraud]
random_undersampled_df = pd.concat([fraud_entries, non_fraud_entries])
random_undersampled_df = random_undersampled_df.sample(frac=1, random_state=42)x = random_undersampled_df.drop("Class", axis=1)
y = random_undersampled_df["Class"]#splitting sub-sampled dataset into train and test set
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=42)#Decision Tree
tree_model = DecisionTreeClassifier(max_depth = 4, criterion = 'entropy')
tree_model.fit(x_train, y_train)#Random Forest Tree
rf = RandomForestClassifier(max_depth = 4)
rf.fit(x_train, y_train)#K-Nearest Neighbors
k = 5
knn = KNeighborsClassifier(n_neighbors = k)
knn.fit(x_train, y_train)#Logistic Regression
lr = LogisticRegression()
lr.fit(x_train, y_train)print('Cross validation score of the Decision Tree model is {}'.format(cross_val_score(tree_model, x_train, y_train, cv=5).mean()))
print('Cross validation of the KNN model is {}'.format(cross_val_score(knn, x_train, y_train, cv=5).mean()))
print('Cross validation score of the Logistic Regression model is {}'.format(cross_val_score(lr, x_train, y_train, cv=5).mean()))
print('Cross validation score of the Random Forest Tree model is {}'.format(cross_val_score(rf, x_train, y_train, cv=5).mean()))ox = df.drop("Class", axis=1)
oy = df["Class"]
#splitting original dataset into train and test set
ox_train, ox_test, oy_train, oy_test = train_test_split(ox, oy, test_size=0.2, random_state=42)print('Accuracy score of the Decision Tree model on the sub-sampled test set is {}'.format(accuracy_score(y_test, tree_model.predict(x_test))))
print('Accuracy score of the KNN model on the sub-sampled test set is {}'.format(accuracy_score(y_test, knn.predict(x_test))))
print('Accuracy score of the Logistic Regression model on the sub-sampled test set is {}'.format(accuracy_score(y_test, lr.predict(x_test))))
print('Accuracy score of the Random Forest Tree model on the sub-sampled test set is {}'.format(accuracy_score(y_test, rf.predict(x_test))))print ('---------------------------------------------')print('Accuracy score of the Decision Tree model on the original test set is {}'.format(accuracy_score(oy_test, tree_model.predict(ox_test))))
print('Accuracy score of the KNN model on the sub-sampled original test set is {}'.format(accuracy_score(oy_test, knn.predict(ox_test))))
print('Accuracy score of the Logistic Regression model on the original test set is {}'.format(accuracy_score(oy_test, lr.predict(ox_test))))
print('Accuracy score of the Random Forest Tree model on the original test set is {}'.format(accuracy_score(oy_test, rf.predict(ox_test))))m = confusion_matrix(y_test, lr.predict(x_test))
ax = sns.heatmap(m, annot=True, cmap='Blues')
ax.set_title('Seaborn Confusion Matrix with labels\n\n');
ax.set_xlabel('\nPredicted Values')
ax.set_ylabel('Actual Values ');
ax.xaxis.set_ticklabels(['False','True'])
ax.yaxis.set_ticklabels(['False','True'])
plt.show()
